



首先说小说原著,实际上小说三部曲互相之间并没有前后联系,更像是三本相同世界观背景下的三个独立故事。唐·科里昂家族的故事仅出现在第一部,而电影也是将这第一本小说的内容改编成了三部电影,电影第一部和第二部选择了原著第一本的部分情节,第三部电影则是自行创作延续了小说第一部的故事线,讲述了迈克尔·科里昂在成为家族领袖后的故事。
所以我们在谈论教父时,主要关注的是教父小说第一部的内容。这本书讲述了唐·科里昂如何从一名贫困的意大利裔美国移民,逐步崛起建立起自己的黑手党家族,后来因为和新崛起的毒品势力发生冲突而遭受重创,最后家族在第二代家主迈克尔的带领下重新崛起,却又在巅峰期激流勇退,从纽约迁去拉斯维加斯完成合法化转型。
书中纽约的黑帮体系,就是通过划分地盘,垄断赌博、保护费、卖淫等黑色生意,建立自己的经济基础,同时通过暴力手段来维护自己的统治地位。而科里昂家族的独特之处就在于,唐·科里昂以教父的形象,为众人排忧解难,并约定人情债,从而在政治和司法界建立了广泛的人脉关系。剧情的主要矛盾就来自于,新崛起的毒品势力向科里昂家族寻求政治保护被拒绝,试图通过杀死科里昂转而扶持桑尼接管家族,从而和科里昂家族达成合作。
剧情的另一大看点,就是唐·科里昂的小儿子迈克尔,从一个叛逆的,完全脱离于家族的美国战争英雄,如何一步步的随着局势的发展而卷入家族危机,最终成长为一位和唐·科里昂风格完全不同,风格狠辣凌厉的教父继承人。
书籍的封面画着一个提线木偶,对应着唐·科里昂经常说的那句话:“每个人都有一种命运”。深居幕后的教父,透过看不见的线索,发掘和操控人们的命运,构建起了家族的势力。
书中对众多人物性格的刻画与成长非常细腻,电影中删去了很多重要配角的故事线,但是电影对于一些重要场面的刻画却确实是堪称传奇经典,也算是各有韵味,值得细致品味。 #book
记录一下最近遇到的一个糟心事儿。
最近两个月开始又开始找工作机会,总的来说很不顺利,托朋友联系了两个内推也是石沉大海。(各位要是有远程工作的机会也请联系 [email protected] )
昨天在 Linkedin 上有个 web3 背景的猎头联系我说有个不错的 contract 工作,就是需要先完成一个 code assessment。这个测试放在 notion 上,指向一个 github repo。但实际上,只要你在本地运行
这个攻击手法相当低劣,低级且恶劣,低级到了随手搜一下
各位都小心一点,不要在本地运行任何来历不明的代码。即使源码里没有搜出可疑的内容也并不可靠,完全可以把攻击代码放在第三方依赖里。vscode 用户可以使用 devcontainer 来执行这些临时项目,能极大的缓解威胁。
最近两个月开始又开始找工作机会,总的来说很不顺利,托朋友联系了两个内推也是石沉大海。(各位要是有远程工作的机会也请联系 [email protected] )
昨天在 Linkedin 上有个 web3 背景的猎头联系我说有个不错的 contract 工作,就是需要先完成一个 code assessment。这个测试放在 notion 上,指向一个 github repo。但实际上,只要你在本地运行
npm start,就会启动恶意脚本,偷偷下载一个 js 脚本并执行。这个攻击手法相当低劣,低级且恶劣,低级到了随手搜一下
eval 就能发现。各位都小心一点,不要在本地运行任何来历不明的代码。即使源码里没有搜出可疑的内容也并不可靠,完全可以把攻击代码放在第三方依赖里。vscode 用户可以使用 devcontainer 来执行这些临时项目,能极大的缓解威胁。
作为一个从业十多年的程序员,我已经半年没手写过一行代码了。上个月大概提交了 20 万行,这个月大概 4 万行。
昨天认真考虑了一下这个现象,我个人认为,虽然 AI 仍然存在显然的不足与缺陷,在非主流领域的代码水平不高甚至有些低劣,但是程序员确实不应该再执着于手写代码和 review 了,自动化、工业化的星辰大海就在眼前,有太多值得探索和尝试的领域。
• 不要再自视优越地吐槽 AI 代码质量差,而是应该探索如何生成高质量的代码。
• 不要再抱怨 AI 代码太多 review 不过来,而是应该探索工业规模的测试和 review 方案。
我认为从 opus-4.7/gpt-5.4 开始,AI 的能力到达了一个分水岭,它能够在严格的约束下,完成它本身并不擅长和理解的工作。可以称之为 harness,不过我不喜欢使用这些转瞬即逝的 fancy words。
软件工程师,作为一个工程师,关注的应该是在限定的资源和时间内,找出和解决问题的能力。对工具本身的钻研,应该服务于解决问题这个根本目标。软件工程会越来越回归一个真实世界的“社会工程问题”,人类拥有上下文难以描述的隐知识,如真实需求、组织结构、资源限制等等,人类用自己的隐知识去驾驭工业化的生产结构,这才是未来的探索之路。
Ps. 目前看来,AI 并不能替换生产者,它只能作为生产者的工具发挥增效。这也许是个好消息,也许是个坏消息,而且不一定对。
昨天认真考虑了一下这个现象,我个人认为,虽然 AI 仍然存在显然的不足与缺陷,在非主流领域的代码水平不高甚至有些低劣,但是程序员确实不应该再执着于手写代码和 review 了,自动化、工业化的星辰大海就在眼前,有太多值得探索和尝试的领域。
• 不要再自视优越地吐槽 AI 代码质量差,而是应该探索如何生成高质量的代码。
• 不要再抱怨 AI 代码太多 review 不过来,而是应该探索工业规模的测试和 review 方案。
我认为从 opus-4.7/gpt-5.4 开始,AI 的能力到达了一个分水岭,它能够在严格的约束下,完成它本身并不擅长和理解的工作。可以称之为 harness,不过我不喜欢使用这些转瞬即逝的 fancy words。
软件工程师,作为一个工程师,关注的应该是在限定的资源和时间内,找出和解决问题的能力。对工具本身的钻研,应该服务于解决问题这个根本目标。软件工程会越来越回归一个真实世界的“社会工程问题”,人类拥有上下文难以描述的隐知识,如真实需求、组织结构、资源限制等等,人类用自己的隐知识去驾驭工业化的生产结构,这才是未来的探索之路。
Ps. 目前看来,AI 并不能替换生产者,它只能作为生产者的工具发挥增效。这也许是个好消息,也许是个坏消息,而且不一定对。
https://www.notion.so/laisky/GitHub-RCE-Vulnerability-CVE-2026-3854-Breakdown-Wiz-Blog-352ba4011a8681c3afdfe340d1a76fd5?source=copy_link
上周看到这个号称仅用 git push 就实现了对 GitHub 服务器的远程控制。这篇文章介绍了攻击原理,没想到实际上这么草台。
网关服务 babeld 接收用户请求,进行身份验证后,就会设置
这么重要的内部权限字段,居然接受明文的用户输入。这种低级错误应该连 GitHub 免费提供的 CodeQL 都能扫出来,太不应该了。
上周看到这个号称仅用 git push 就实现了对 GitHub 服务器的远程控制。这篇文章介绍了攻击原理,没想到实际上这么草台。
网关服务 babeld 接收用户请求,进行身份验证后,就会设置
X-Stat header 作为内部服务通信的关键权限信息。然而,X-Stat 作为重要的内部属性,居然允许直接拼接外部的用户输入,而且在拼接时没有进行 sanitize 处理,导致攻击者可以简单的使用 ; 来实现任意注入。这么重要的内部权限字段,居然接受明文的用户输入。这种低级错误应该连 GitHub 免费提供的 CodeQL 都能扫出来,太不应该了。

https://laisky.notion.site/VMware-e1000-vmxnet3-34cba4011a8680ea9242e1f93d990b17?source=copy_link
一个小笔记。我家里用一台 windows 11 主机,通过 vmware workstation pro 运行了一些虚拟机,然后通过 tailscale 和我的其他 VPS 打通。
近期某些虚拟机在网络流量较大时会出现网络中断,表现为一个 CPU 完全跑满,外网延迟增加到 15s 以上,重启 tailscale 后能够恢复。
让 codex app 去帮我修复,它将 e1000 网卡修改为了 vmxnet3,目前已经用了一周左右,很稳定,没有再出现问题。整个故障的排查、修复和记笔记都是 codex app 完成的,不得不说 codex app 完美解决了我不懂也不想折腾 windows 的局限😂。
一个小笔记。我家里用一台 windows 11 主机,通过 vmware workstation pro 运行了一些虚拟机,然后通过 tailscale 和我的其他 VPS 打通。
近期某些虚拟机在网络流量较大时会出现网络中断,表现为一个 CPU 完全跑满,外网延迟增加到 15s 以上,重启 tailscale 后能够恢复。
让 codex app 去帮我修复,它将 e1000 网卡修改为了 vmxnet3,目前已经用了一周左右,很稳定,没有再出现问题。整个故障的排查、修复和记笔记都是 codex app 完成的,不得不说 codex app 完美解决了我不懂也不想折腾 windows 的局限😂。

简单分享下我是怎么花最少的钱,但是又非常重度、高频的依赖 AI coding 的。
我目前的订阅是,最便宜的 copilot 和 codex。这两个的特点在于:codex 是按量付费的,而 copilot 是按次付费的。这个区别是最关键的,如果你更喜欢 cc,那么你可以把本文中的 codex 替换为 cc,一样的逻辑。
而作为 coding,其实工作可以拆分为两大类型,我相信其他大部分文字工作也可以这么拆分:
1. 计划阶段:此时会涉及非常高频交流,但是每次交流的内容都不多,你可以使用 codex 的最高思考模式,写下最核心的关键逻辑
2. 实施阶段:这是广义的实施,包括收集资料、撰写文档、coding、testing、debug 反复调试 都可以视为实施。
copilot 的按次付费,使它成为实施阶段的最佳性价比选择。发送一次 prompt 算一次费用,只要 agent loop 没有结束,期间一切的 tools 调用都不计费。只要通过 prompt 给它输入我们之前和 codex 聊好的 spec,接下来就让 copilot 吭哧吭哧的去把最脏最累但是没有特别高思考难度的活全部干完。
⚠️很可惜,copilot 已经取消了按次计费,而且设置了严格的基于用量的 limit,黄金时代结束了。
具体怎么让 copilot(我最爱用 gpt-5.4) 能够不中断的,一次性干完最多活,这里面需要调试 copilot 的 instructions,具体就不展开了,各有各的方法。但是我这里推荐一下我的 remote MCP server https://mcp.laisky.com/tools/get_user_requests
其中的这个 get_user_requests tool,相当于是在 MCP 上维护了一个 TODO list,而且是你可以动态编辑的 TODO list。你只需要在 instructions 里要求 copilot 频繁的,在每次子任务结束后,都去调用 get_user_requests,而且必须在连续两次调用 get_user_requests 为空后才能返回。你其实就拥有了在不打断 agent 一次任务的前提下,和 agent 沟通的能力,而利用这个能力,你就可以让 copilot 在一次计费里,干掉尽可能多的活。
举个我的例子,极端情况下,我很可能一天只需要跑 3 次 copilot,中间会停两次是因为我要吃午饭和晚饭,没精力去盯着 get_user_requests 的 requests queue 了。我甚至经常跑出 copilot 的 tokens quota limit,会被停用一段时间,估计很多人可能都不知道 copilot 还有limit 吧😂
Copilot 还有个我非常喜欢的地方是,如果你把配额用超了,它可以自动转为按次计费,每一次请求约为 $0.03 USD,很实惠。
如果你非常有钱,或者公司给无限的订阅资金,可以忽略这一条。和穷人们共勉。
我目前的订阅是,最便宜的 copilot 和 codex。这两个的特点在于:codex 是按量付费的,而 copilot 是按次付费的。这个区别是最关键的,如果你更喜欢 cc,那么你可以把本文中的 codex 替换为 cc,一样的逻辑。
而作为 coding,其实工作可以拆分为两大类型,我相信其他大部分文字工作也可以这么拆分:
1. 计划阶段:此时会涉及非常高频交流,但是每次交流的内容都不多,你可以使用 codex 的最高思考模式,写下最核心的关键逻辑
2. 实施阶段:这是广义的实施,包括收集资料、撰写文档、coding、testing、debug 反复调试 都可以视为实施。
⚠️很可惜,copilot 已经取消了按次计费,而且设置了严格的基于用量的 limit,黄金时代结束了。
具体怎么让 copilot(我最爱用 gpt-5.4) 能够不中断的,一次性干完最多活,这里面需要调试 copilot 的 instructions,具体就不展开了,各有各的方法。但是我这里推荐一下我的 remote MCP server https://mcp.laisky.com/tools/get_user_requests
其中的这个 get_user_requests tool,相当于是在 MCP 上维护了一个 TODO list,而且是你可以动态编辑的 TODO list。你只需要在 instructions 里要求 copilot 频繁的,在每次子任务结束后,都去调用 get_user_requests,而且必须在连续两次调用 get_user_requests 为空后才能返回。你其实就拥有了在不打断 agent 一次任务的前提下,和 agent 沟通的能力,而利用这个能力,你就可以让 copilot 在一次计费里,干掉尽可能多的活。
举个我的例子,极端情况下,我很可能一天只需要跑 3 次 copilot,中间会停两次是因为我要吃午饭和晚饭,没精力去盯着 get_user_requests 的 requests queue 了。我甚至经常跑出 copilot 的 tokens quota limit,会被停用一段时间,估计很多人可能都不知道 copilot 还有limit 吧😂
Copilot 还有个我非常喜欢的地方是,如果你把配额用超了,它可以自动转为按次计费,每一次请求约为 $0.03 USD,很实惠。
如果你非常有钱,或者公司给无限的订阅资金,可以忽略这一条。和穷人们共勉。
https://developer.1password.com/docs/service-accounts/use-with-1password-cli/
最近折腾的一件事就是把服务器部署的密钥全部用 1Password 管理了。
以前的做法比较粗糙,我有一个 private github repo 专门存放各种密钥,每台主机上都在固定的位置 clone 这个 repo。
现在我在 1Password 上创建了一个 vault 专门存放这些密钥,然后为每一台主机创建一个 service account,给它访问这个 vault 的权限。每台主机上安装 1Password CLI,并使用对应的 service account 登录,就可以用下面的形式定义密钥了。
对于那些通过环境变量获得密钥的应用,直接使用
如果你不喜欢环境变量,也可以通过 1Password 的 SDK 在代码里直接获取密钥值。
这样做的优点是,可以在 1pwd 的网站上通过吊销 service account 的访问权限来快速撤销某台主机的密钥访问。可惜就是 audit log 仅对 Business 版本可用,还有就是 service account 的权限粒度仅支持 vault 级别,聊胜于无吧,对于个人服务来说至少比裸奔强多了。
最近折腾的一件事就是把服务器部署的密钥全部用 1Password 管理了。
以前的做法比较粗糙,我有一个 private github repo 专门存放各种密钥,每台主机上都在固定的位置 clone 这个 repo。
现在我在 1Password 上创建了一个 vault 专门存放这些密钥,然后为每一台主机创建一个 service account,给它访问这个 vault 的权限。每台主机上安装 1Password CLI,并使用对应的 service account 登录,就可以用下面的形式定义密钥了。
SESSION_SECRET=op://configs/oneapi/SESSION_SECRET
SQL_DSN=op://configs/oneapi/SQL_DSN
LOG_PUSH_TOKEN=op://configs/oneapi/LOG_PUSH_TOKEN对于那些通过环境变量获得密钥的应用,直接使用
op run --env-file=./one-api/b1.env -- <ORIGINAL_COMMAND> 就可以了,1pwd cli 会自动解析这些环境变量并替换成对应的密钥值。如果你不喜欢环境变量,也可以通过 1Password 的 SDK 在代码里直接获取密钥值。
这样做的优点是,可以在 1pwd 的网站上通过吊销 service account 的访问权限来快速撤销某台主机的密钥访问。可惜就是 audit log 仅对 Business 版本可用,还有就是 service account 的权限粒度仅支持 vault 级别,聊胜于无吧,对于个人服务来说至少比裸奔强多了。

https://laisky.notion.site/Effective-context-engineering-for-AI-agents-Anthropic-2ddba4011a868170ac2ddd9017afadde?source=copy_link
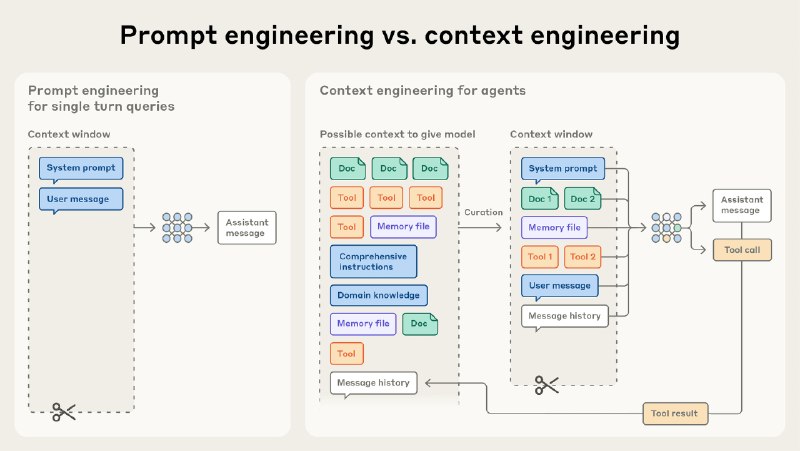
Anthropic 介绍 context engineering 的文章。
- prompt engineering 主要关注如何撰写 system prompt。
- context engineering 则关注 agent 相关的所有工程问题。
注意力是稀缺的,context 过长,反而会导致模型能力下降(context rot)。
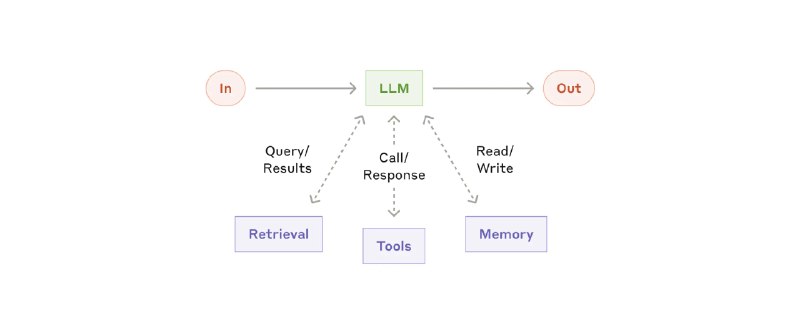
所谓 Agent,就是在 loop 内自动调用工具的 LLM。
context 注入的两种方式:
1. 在推理前,利用 RAG 检索和注入 context(延迟低)
2. 在 Agent 运行的过程中,通过 tools 自动检索和读取(可以 progressive disclosure,信息更准确)。推荐使用类文件系统的信息索引方式,这些文件的路径本身,也包含重要的信息。
long-horizon tasks 的 context 优化工具箱:
- compaction:压缩 context,仅保留关键信息。记忆信息拆分不同的 TTL 层级,然后按照不同的文件路径进行组织和存储。
- structured note-taking:context 外部的记忆工具,如 TODO list
- multi-agent architectures:拆分子任务,coordinator 仅派发任务和接收 sub-agent worker 的摘要。不要试图用一个上下文维护大型项目的全部信息。
Anthropic 还有一篇 Effective harnesses for long-running agents 感觉只是对本文的 multi-agent architectures 的一些实践小经验总结,信息量不多。
👆 prev
Anthropic 介绍 context engineering 的文章。
- prompt engineering 主要关注如何撰写 system prompt。
- context engineering 则关注 agent 相关的所有工程问题。
注意力是稀缺的,context 过长,反而会导致模型能力下降(context rot)。
所谓 Agent,就是在 loop 内自动调用工具的 LLM。
context 注入的两种方式:
1. 在推理前,利用 RAG 检索和注入 context(延迟低)
2. 在 Agent 运行的过程中,通过 tools 自动检索和读取(可以 progressive disclosure,信息更准确)。推荐使用类文件系统的信息索引方式,这些文件的路径本身,也包含重要的信息。
long-horizon tasks 的 context 优化工具箱:
- compaction:压缩 context,仅保留关键信息。记忆信息拆分不同的 TTL 层级,然后按照不同的文件路径进行组织和存储。
- structured note-taking:context 外部的记忆工具,如 TODO list
- multi-agent architectures:拆分子任务,coordinator 仅派发任务和接收 sub-agent worker 的摘要。不要试图用一个上下文维护大型项目的全部信息。
Anthropic 还有一篇 Effective harnesses for long-running agents 感觉只是对本文的 multi-agent architectures 的一些实践小经验总结,信息量不多。
👆 prev
https://laisky.notion.site/Building-Effective-AI-Agents-Anthropic-2ddba4011a868146b90bf176d265cf81?source=copy_link
虽然人们喜欢说 agent 取代了 workflow,但是 agent 本身其实也是由一系列的 workflow 最小功能单元组成的。
区别在于,workflow 是由固定的逻辑和工具组成的。而 agent 则是由 LLM 动态选择工具和生成逻辑组成的。
本文介绍了用来构建 agent 的 workflow 功能单元:
- chain: 最常见的串行流水线
- routing: 动态判断任务类型,传递给不同的下游
- parallel: 并行处理多个任务
- orchestrating: 类似于 parallel,但是下游的任务是动态生成的,而不是预定义的并行流水线
- evaluator-optimizer: 如果存在一个清晰的验收标准,那么添加一个 feedback loop 可以显著提升输出质量
agents 的执行路径是动态生成的,无法预测准确执行步数和资源消耗。但是为了防止死循环等问题,应该对资源消耗、步数等预设停机条件。
👇 next
虽然人们喜欢说 agent 取代了 workflow,但是 agent 本身其实也是由一系列的 workflow 最小功能单元组成的。
区别在于,workflow 是由固定的逻辑和工具组成的。而 agent 则是由 LLM 动态选择工具和生成逻辑组成的。
本文介绍了用来构建 agent 的 workflow 功能单元:
- chain: 最常见的串行流水线
- routing: 动态判断任务类型,传递给不同的下游
- parallel: 并行处理多个任务
- orchestrating: 类似于 parallel,但是下游的任务是动态生成的,而不是预定义的并行流水线
- evaluator-optimizer: 如果存在一个清晰的验收标准,那么添加一个 feedback loop 可以显著提升输出质量
agents 的执行路径是动态生成的,无法预测准确执行步数和资源消耗。但是为了防止死循环等问题,应该对资源消耗、步数等预设停机条件。
👇 next
免费用户可以并行 2 个任务(声称是 3 个,实际上只能运行 2 个😓)。
选择好项目、branch 后,点击下面预设的 Performance、Design、Security 生成 prompt。然后建议把执行计划改为 Start(单次执行),而不是默认的 Scheduled,防止占用有限的任务配额。(如果你是尊贵的付费用户那请忽略)
免费用户只能选用 gemini-3-flash。我个人的使用体验是,它找 BUG 的能力非常强,但是修复的能力比较弱。我目前的使用方法是,把 BUG REPORT 粘贴给其他更强力的模型来修复,最近每天都能找出很多陈年老 BUG,每天都在打击我身为老程序员的自尊😭。
不过换个思路,这也是一个去刷开源项目 PR 的机会。
学习了一下 Anthropic 的 Agent Skills 设计。通过在文件系统中定义一套文件结构,让 Agent 可以按需加载(Progressive Disclosure)相关的技能描述和脚本。
Skills 通过 metadata + instructions + scripts 定义一个领域技能。Agent 在启动时全量加载 metadatas,然后按需加载 instructions,而 instructions 会指导 agent 调用 scripts。scripts 的内容不会被加载,只有 output 会被加载进入 context。
通过一个三层的 lazy-loading 设计,相当于 RAG + tools,既减少了对 context 的占用,也赋予了 agent 工具调用的能力。
但是我认为,Anthropic 没有选择优化 MCP,而是硬造了一个新轮子,给 Agent 世界带来更多的混乱,有些可惜。
Skills 的功能完全可以通过对 MCP 的些微优化来实现,只需要在 MCP 中增加两个 tools:
-
find_skills(query): 根据 query 查找相关的 skills metadata 列表-
describe_skill(skill_id): 根据 skill_id 获取对应的 instructions。instructions 内会指导 agent 如果通过调用其他 tools 完成任务。实际上,已经有很多人发布了相关的 skills-mcp 工具,只要搜索
github skills-mcp 就能找到很多。https://laisky.notion.site/msanft-CVE-2025-55182-Explanation-and-full-RCE-PoC-for-CVE-2025-55182-2c2ba4011a8681b89b60cf02827a6276?source=copy_link
之前提到的 next/react 严重服务端 RCE 漏洞 CVE-2025-55182
攻击者传递两个 chunk。chunk 0 作为攻击载体,chunk 1 作为正常 chunk,然后:
1. 利用自定义 then 将 chunk.prototype.then 挂载到 chunk 0,使得 chunk 0 变成 thenable,成为可被执行的 Promise
2. chunk 1 中,通过 $@0,将 chunk 0 作为 decodeReplyFromBusboy 的返回值,被 await 执行(thenable 对象都会被作为 Promise 而被 await 执行)
3. chunk0 中,通过自定义 react 状态机 status,触发 initializeModelChunk 中对 _response 的读取
4. 在 chunk 0 中,$B 会让 react 调用 response._formData.get()。但是 chunk 0 自定义了 _response 中的 _formData 和 _get,导致读取 _response body 的操作变成了一次代码执行
在我看来严重隐患似乎存在于两个地方:
1. 允许用户操作 prototype 的 function constructor,可以通过限制仅允许访问 ownProperty 来抑制
2. $@0 直接将 chunk 返回,而且 react 会将这个 chunk 视为一个可信的内部对象,这个对象通过 status 来控制状态,_response、_get 来控制数据。也就是说,外部的不可信输入直接控制了状态和数据。我觉得这个设计的问题可比 prototype 的访问越权严重多了。
之前提到的 next/react 严重服务端 RCE 漏洞 CVE-2025-55182
攻击者传递两个 chunk。chunk 0 作为攻击载体,chunk 1 作为正常 chunk,然后:
1. 利用自定义 then 将 chunk.prototype.then 挂载到 chunk 0,使得 chunk 0 变成 thenable,成为可被执行的 Promise
2. chunk 1 中,通过 $@0,将 chunk 0 作为 decodeReplyFromBusboy 的返回值,被 await 执行(thenable 对象都会被作为 Promise 而被 await 执行)
3. chunk0 中,通过自定义 react 状态机 status,触发 initializeModelChunk 中对 _response 的读取
4. 在 chunk 0 中,$B 会让 react 调用 response._formData.get()。但是 chunk 0 自定义了 _response 中的 _formData 和 _get,导致读取 _response body 的操作变成了一次代码执行
在我看来严重隐患似乎存在于两个地方:
1. 允许用户操作 prototype 的 function constructor,可以通过限制仅允许访问 ownProperty 来抑制
2. $@0 直接将 chunk 返回,而且 react 会将这个 chunk 视为一个可信的内部对象,这个对象通过 status 来控制状态,_response、_get 来控制数据。也就是说,外部的不可信输入直接控制了状态和数据。我觉得这个设计的问题可比 prototype 的访问越权严重多了。

https://www.notion.so/laisky/Cloudflare-outage-on-November-18-2025-2bcba4011a8681e79964ff8933d3c5b2
CloudFlare 对于 2025-11-18 的故障报告。边缘服务设定了严格的内存限制,其中bot modules 限制了能够处理的规则行数。当接收到超过限制的规则文件后导致 panic。而新的 FL2 系统在 bot modules panic 时,没能仅降级 bot 服务,而是全链路 panic,导致全站 5xx。旧版的 FL 系统就很好的仅降级了 bot score 服务,没有对用户业务造成中断。
我个人认为的经验教训就是:
1. bot modules panic 不是问题,有助于尽早暴露错误,但是必须被隔离。
2. FL2 在 bot modules panic 后,应该进行告警和服务降级,而不是整体 panic(Blast Radius)
3. chaos engineering 应该对各种交互都进行测试,比如文件过大、格式错误等等。任何关键服务都不应该信任外部输入,即使这个外部输入来自友方。
CloudFlare 对于 2025-11-18 的故障报告。边缘服务设定了严格的内存限制,其中bot modules 限制了能够处理的规则行数。当接收到超过限制的规则文件后导致 panic。而新的 FL2 系统在 bot modules panic 时,没能仅降级 bot 服务,而是全链路 panic,导致全站 5xx。旧版的 FL 系统就很好的仅降级了 bot score 服务,没有对用户业务造成中断。
我个人认为的经验教训就是:
1. bot modules panic 不是问题,有助于尽早暴露错误,但是必须被隔离。
2. FL2 在 bot modules panic 后,应该进行告警和服务降级,而不是整体 panic(Blast Radius)
3. chaos engineering 应该对各种交互都进行测试,比如文件过大、格式错误等等。任何关键服务都不应该信任外部输入,即使这个外部输入来自友方。
https://x.com/0xdizz/status/1996425682717720971?s=20 用 react 写服务端的赶紧自查一下。我这种坚持不碰前端佬写的服务端的后端仔有福了🐶
👉 next
👉 next
https://laisky.notion.site/Time-Zone-Handling-for-Software-Engineers-A-Comprehensive-Technical-Handbook-2b3ba4011a8680f2b895f51f19b62dad?source=copy_link
让 DeepResearch 帮忙总结了一篇关于时区的报告。最近都不怎么喜欢搜索文章了,想到什么问题就扔给 DeepResearch 让它给我写一篇报告。
因为中国只有一个时区,很多开发人员都会忽略时区问题,我加入很多团队都帮忙处理过时区相关的问题(另一个经常被忽略的是编码问题)。
首先,在用户看不见的后端使用 UTC 时间是一个很好的习惯,但是 UTC 并不是银弹,并不能取代时区。
时区并不仅仅只是相对于 UTC 的一个固定偏移量,而是代表某一地区时间变化的历史和规则。比如某地可能在某一个时刻,决定让时钟拨快或拨慢一小时,这些规则的处理都必须依赖准确的当地时区数据,而不是 UTC 能够解决的。同理,不同的时区也不能随意的互相替换,即使在当前时刻它们的 UTC 偏移量相同。
比如关于冬令时/夏令时的调整,就会导致当地的某一时刻在两个不同时区出现两次,而另一个时刻则根本不存在。
关于时间的存储,UTC 仅能满足对于时刻的存储需求。只要涉及到当地事件、时间的相对计算、日程安排(牵涉星期、月份日期、节假日)等,都必须结合使用当地时区信息进行计算。而且由于用户可能会进行跨时区迁移,最好能够让用户自行选择自己的时区信息(比如 Google Calendar 的做法)。
重点:
* 如果你只需要时刻信息(Instant),使用 UTC 存储和传输是一个好习惯。
* 但是如果你需要任何基于当地时间的计算,必须携带时区信息。
BTW,时区的英文缩写存在重名,在沟通中不要使用简写。比如 CST 既可以是 China Standard Time 也可以是 Central Standard Time。 我以前和美国的团队协作时就遇到过歧义。
让 DeepResearch 帮忙总结了一篇关于时区的报告。最近都不怎么喜欢搜索文章了,想到什么问题就扔给 DeepResearch 让它给我写一篇报告。
因为中国只有一个时区,很多开发人员都会忽略时区问题,我加入很多团队都帮忙处理过时区相关的问题(另一个经常被忽略的是编码问题)。
首先,在用户看不见的后端使用 UTC 时间是一个很好的习惯,但是 UTC 并不是银弹,并不能取代时区。
时区并不仅仅只是相对于 UTC 的一个固定偏移量,而是代表某一地区时间变化的历史和规则。比如某地可能在某一个时刻,决定让时钟拨快或拨慢一小时,这些规则的处理都必须依赖准确的当地时区数据,而不是 UTC 能够解决的。同理,不同的时区也不能随意的互相替换,即使在当前时刻它们的 UTC 偏移量相同。
比如关于冬令时/夏令时的调整,就会导致当地的某一时刻在两个不同时区出现两次,而另一个时刻则根本不存在。
关于时间的存储,UTC 仅能满足对于时刻的存储需求。只要涉及到当地事件、时间的相对计算、日程安排(牵涉星期、月份日期、节假日)等,都必须结合使用当地时区信息进行计算。而且由于用户可能会进行跨时区迁移,最好能够让用户自行选择自己的时区信息(比如 Google Calendar 的做法)。
重点:
* 如果你只需要时刻信息(Instant),使用 UTC 存储和传输是一个好习惯。
* 但是如果你需要任何基于当地时间的计算,必须携带时区信息。
BTW,时区的英文缩写存在重名,在沟通中不要使用简写。比如 CST 既可以是 China Standard Time 也可以是 Central Standard Time。 我以前和美国的团队协作时就遇到过歧义。
