https://www.notion.so/laisky/GitHub-RCE-Vulnerability-CVE-2026-3854-Breakdown-Wiz-Blog-352ba4011a8681c3afdfe340d1a76fd5?source=copy_link
上周看到这个号称仅用 git push 就实现了对 GitHub 服务器的远程控制。这篇文章介绍了攻击原理,没想到实际上这么草台。
网关服务 babeld 接收用户请求,进行身份验证后,就会设置
这么重要的内部权限字段,居然接受明文的用户输入。这种低级错误应该连 GitHub 免费提供的 CodeQL 都能扫出来,太不应该了。
上周看到这个号称仅用 git push 就实现了对 GitHub 服务器的远程控制。这篇文章介绍了攻击原理,没想到实际上这么草台。
网关服务 babeld 接收用户请求,进行身份验证后,就会设置
X-Stat header 作为内部服务通信的关键权限信息。然而,X-Stat 作为重要的内部属性,居然允许直接拼接外部的用户输入,而且在拼接时没有进行 sanitize 处理,导致攻击者可以简单的使用 ; 来实现任意注入。这么重要的内部权限字段,居然接受明文的用户输入。这种低级错误应该连 GitHub 免费提供的 CodeQL 都能扫出来,太不应该了。

https://laisky.notion.site/VMware-e1000-vmxnet3-34cba4011a8680ea9242e1f93d990b17?source=copy_link
一个小笔记。我家里用一台 windows 11 主机,通过 vmware workstation pro 运行了一些虚拟机,然后通过 tailscale 和我的其他 VPS 打通。
近期某些虚拟机在网络流量较大时会出现网络中断,表现为一个 CPU 完全跑满,外网延迟增加到 15s 以上,重启 tailscale 后能够恢复。
让 codex app 去帮我修复,它将 e1000 网卡修改为了 vmxnet3,目前已经用了一周左右,很稳定,没有再出现问题。整个故障的排查、修复和记笔记都是 codex app 完成的,不得不说 codex app 完美解决了我不懂也不想折腾 windows 的局限😂。
一个小笔记。我家里用一台 windows 11 主机,通过 vmware workstation pro 运行了一些虚拟机,然后通过 tailscale 和我的其他 VPS 打通。
近期某些虚拟机在网络流量较大时会出现网络中断,表现为一个 CPU 完全跑满,外网延迟增加到 15s 以上,重启 tailscale 后能够恢复。
让 codex app 去帮我修复,它将 e1000 网卡修改为了 vmxnet3,目前已经用了一周左右,很稳定,没有再出现问题。整个故障的排查、修复和记笔记都是 codex app 完成的,不得不说 codex app 完美解决了我不懂也不想折腾 windows 的局限😂。

简单分享下我是怎么花最少的钱,但是又非常重度、高频的依赖 AI coding 的。
我目前的订阅是,最便宜的 copilot 和 codex。这两个的特点在于:codex 是按量付费的,而 copilot 是按次付费的。这个区别是最关键的,如果你更喜欢 cc,那么你可以把本文中的 codex 替换为 cc,一样的逻辑。
而作为 coding,其实工作可以拆分为两大类型,我相信其他大部分文字工作也可以这么拆分:
1. 计划阶段:此时会涉及非常高频交流,但是每次交流的内容都不多,你可以使用 codex 的最高思考模式,写下最核心的关键逻辑
2. 实施阶段:这是广义的实施,包括收集资料、撰写文档、coding、testing、debug 反复调试 都可以视为实施。
copilot 的按次付费,使它成为实施阶段的最佳性价比选择。发送一次 prompt 算一次费用,只要 agent loop 没有结束,期间一切的 tools 调用都不计费。只要通过 prompt 给它输入我们之前和 codex 聊好的 spec,接下来就让 copilot 吭哧吭哧的去把最脏最累但是没有特别高思考难度的活全部干完。
⚠️很可惜,copilot 已经取消了按次计费,而且设置了严格的基于用量的 limit,黄金时代结束了。
具体怎么让 copilot(我最爱用 gpt-5.4) 能够不中断的,一次性干完最多活,这里面需要调试 copilot 的 instructions,具体就不展开了,各有各的方法。但是我这里推荐一下我的 remote MCP server https://mcp.laisky.com/tools/get_user_requests
其中的这个 get_user_requests tool,相当于是在 MCP 上维护了一个 TODO list,而且是你可以动态编辑的 TODO list。你只需要在 instructions 里要求 copilot 频繁的,在每次子任务结束后,都去调用 get_user_requests,而且必须在连续两次调用 get_user_requests 为空后才能返回。你其实就拥有了在不打断 agent 一次任务的前提下,和 agent 沟通的能力,而利用这个能力,你就可以让 copilot 在一次计费里,干掉尽可能多的活。
举个我的例子,极端情况下,我很可能一天只需要跑 3 次 copilot,中间会停两次是因为我要吃午饭和晚饭,没精力去盯着 get_user_requests 的 requests queue 了。我甚至经常跑出 copilot 的 tokens quota limit,会被停用一段时间,估计很多人可能都不知道 copilot 还有limit 吧😂
Copilot 还有个我非常喜欢的地方是,如果你把配额用超了,它可以自动转为按次计费,每一次请求约为 $0.03 USD,很实惠。
如果你非常有钱,或者公司给无限的订阅资金,可以忽略这一条。和穷人们共勉。
我目前的订阅是,最便宜的 copilot 和 codex。这两个的特点在于:codex 是按量付费的,而 copilot 是按次付费的。这个区别是最关键的,如果你更喜欢 cc,那么你可以把本文中的 codex 替换为 cc,一样的逻辑。
而作为 coding,其实工作可以拆分为两大类型,我相信其他大部分文字工作也可以这么拆分:
1. 计划阶段:此时会涉及非常高频交流,但是每次交流的内容都不多,你可以使用 codex 的最高思考模式,写下最核心的关键逻辑
2. 实施阶段:这是广义的实施,包括收集资料、撰写文档、coding、testing、debug 反复调试 都可以视为实施。
⚠️很可惜,copilot 已经取消了按次计费,而且设置了严格的基于用量的 limit,黄金时代结束了。
具体怎么让 copilot(我最爱用 gpt-5.4) 能够不中断的,一次性干完最多活,这里面需要调试 copilot 的 instructions,具体就不展开了,各有各的方法。但是我这里推荐一下我的 remote MCP server https://mcp.laisky.com/tools/get_user_requests
其中的这个 get_user_requests tool,相当于是在 MCP 上维护了一个 TODO list,而且是你可以动态编辑的 TODO list。你只需要在 instructions 里要求 copilot 频繁的,在每次子任务结束后,都去调用 get_user_requests,而且必须在连续两次调用 get_user_requests 为空后才能返回。你其实就拥有了在不打断 agent 一次任务的前提下,和 agent 沟通的能力,而利用这个能力,你就可以让 copilot 在一次计费里,干掉尽可能多的活。
举个我的例子,极端情况下,我很可能一天只需要跑 3 次 copilot,中间会停两次是因为我要吃午饭和晚饭,没精力去盯着 get_user_requests 的 requests queue 了。我甚至经常跑出 copilot 的 tokens quota limit,会被停用一段时间,估计很多人可能都不知道 copilot 还有limit 吧😂
Copilot 还有个我非常喜欢的地方是,如果你把配额用超了,它可以自动转为按次计费,每一次请求约为 $0.03 USD,很实惠。
如果你非常有钱,或者公司给无限的订阅资金,可以忽略这一条。和穷人们共勉。
https://developer.1password.com/docs/service-accounts/use-with-1password-cli/
最近折腾的一件事就是把服务器部署的密钥全部用 1Password 管理了。
以前的做法比较粗糙,我有一个 private github repo 专门存放各种密钥,每台主机上都在固定的位置 clone 这个 repo。
现在我在 1Password 上创建了一个 vault 专门存放这些密钥,然后为每一台主机创建一个 service account,给它访问这个 vault 的权限。每台主机上安装 1Password CLI,并使用对应的 service account 登录,就可以用下面的形式定义密钥了。
对于那些通过环境变量获得密钥的应用,直接使用
如果你不喜欢环境变量,也可以通过 1Password 的 SDK 在代码里直接获取密钥值。
这样做的优点是,可以在 1pwd 的网站上通过吊销 service account 的访问权限来快速撤销某台主机的密钥访问。可惜就是 audit log 仅对 Business 版本可用,还有就是 service account 的权限粒度仅支持 vault 级别,聊胜于无吧,对于个人服务来说至少比裸奔强多了。
最近折腾的一件事就是把服务器部署的密钥全部用 1Password 管理了。
以前的做法比较粗糙,我有一个 private github repo 专门存放各种密钥,每台主机上都在固定的位置 clone 这个 repo。
现在我在 1Password 上创建了一个 vault 专门存放这些密钥,然后为每一台主机创建一个 service account,给它访问这个 vault 的权限。每台主机上安装 1Password CLI,并使用对应的 service account 登录,就可以用下面的形式定义密钥了。
SESSION_SECRET=op://configs/oneapi/SESSION_SECRET
SQL_DSN=op://configs/oneapi/SQL_DSN
LOG_PUSH_TOKEN=op://configs/oneapi/LOG_PUSH_TOKEN对于那些通过环境变量获得密钥的应用,直接使用
op run --env-file=./one-api/b1.env -- <ORIGINAL_COMMAND> 就可以了,1pwd cli 会自动解析这些环境变量并替换成对应的密钥值。如果你不喜欢环境变量,也可以通过 1Password 的 SDK 在代码里直接获取密钥值。
这样做的优点是,可以在 1pwd 的网站上通过吊销 service account 的访问权限来快速撤销某台主机的密钥访问。可惜就是 audit log 仅对 Business 版本可用,还有就是 service account 的权限粒度仅支持 vault 级别,聊胜于无吧,对于个人服务来说至少比裸奔强多了。

https://laisky.notion.site/Effective-context-engineering-for-AI-agents-Anthropic-2ddba4011a868170ac2ddd9017afadde?source=copy_link
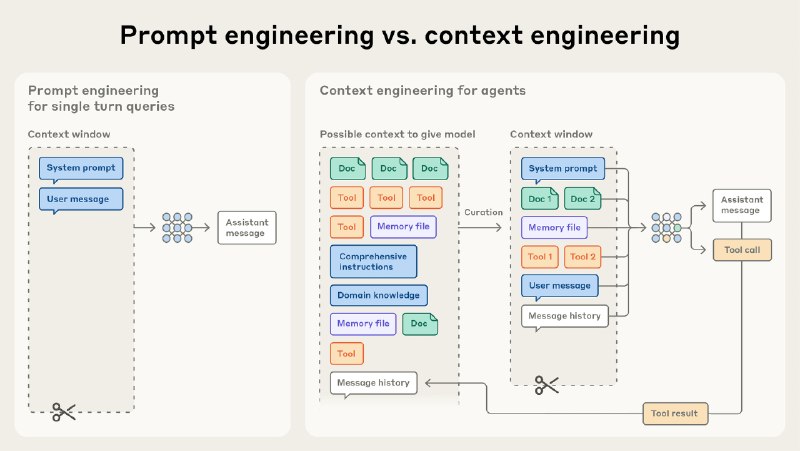
Anthropic 介绍 context engineering 的文章。
- prompt engineering 主要关注如何撰写 system prompt。
- context engineering 则关注 agent 相关的所有工程问题。
注意力是稀缺的,context 过长,反而会导致模型能力下降(context rot)。
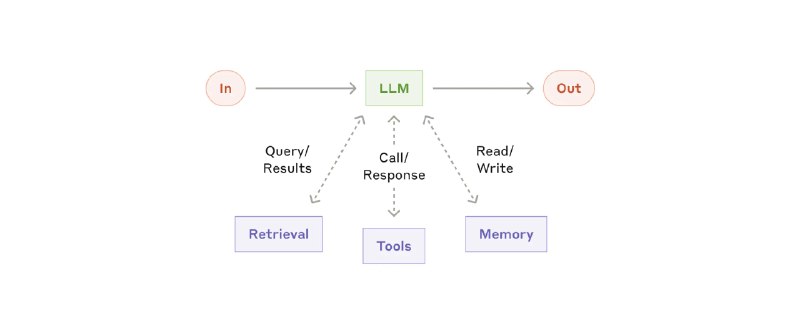
所谓 Agent,就是在 loop 内自动调用工具的 LLM。
context 注入的两种方式:
1. 在推理前,利用 RAG 检索和注入 context(延迟低)
2. 在 Agent 运行的过程中,通过 tools 自动检索和读取(可以 progressive disclosure,信息更准确)。推荐使用类文件系统的信息索引方式,这些文件的路径本身,也包含重要的信息。
long-horizon tasks 的 context 优化工具箱:
- compaction:压缩 context,仅保留关键信息。记忆信息拆分不同的 TTL 层级,然后按照不同的文件路径进行组织和存储。
- structured note-taking:context 外部的记忆工具,如 TODO list
- multi-agent architectures:拆分子任务,coordinator 仅派发任务和接收 sub-agent worker 的摘要。不要试图用一个上下文维护大型项目的全部信息。
Anthropic 还有一篇 Effective harnesses for long-running agents 感觉只是对本文的 multi-agent architectures 的一些实践小经验总结,信息量不多。
👆 prev
Anthropic 介绍 context engineering 的文章。
- prompt engineering 主要关注如何撰写 system prompt。
- context engineering 则关注 agent 相关的所有工程问题。
注意力是稀缺的,context 过长,反而会导致模型能力下降(context rot)。
所谓 Agent,就是在 loop 内自动调用工具的 LLM。
context 注入的两种方式:
1. 在推理前,利用 RAG 检索和注入 context(延迟低)
2. 在 Agent 运行的过程中,通过 tools 自动检索和读取(可以 progressive disclosure,信息更准确)。推荐使用类文件系统的信息索引方式,这些文件的路径本身,也包含重要的信息。
long-horizon tasks 的 context 优化工具箱:
- compaction:压缩 context,仅保留关键信息。记忆信息拆分不同的 TTL 层级,然后按照不同的文件路径进行组织和存储。
- structured note-taking:context 外部的记忆工具,如 TODO list
- multi-agent architectures:拆分子任务,coordinator 仅派发任务和接收 sub-agent worker 的摘要。不要试图用一个上下文维护大型项目的全部信息。
Anthropic 还有一篇 Effective harnesses for long-running agents 感觉只是对本文的 multi-agent architectures 的一些实践小经验总结,信息量不多。
👆 prev
https://laisky.notion.site/Building-Effective-AI-Agents-Anthropic-2ddba4011a868146b90bf176d265cf81?source=copy_link
虽然人们喜欢说 agent 取代了 workflow,但是 agent 本身其实也是由一系列的 workflow 最小功能单元组成的。
区别在于,workflow 是由固定的逻辑和工具组成的。而 agent 则是由 LLM 动态选择工具和生成逻辑组成的。
本文介绍了用来构建 agent 的 workflow 功能单元:
- chain: 最常见的串行流水线
- routing: 动态判断任务类型,传递给不同的下游
- parallel: 并行处理多个任务
- orchestrating: 类似于 parallel,但是下游的任务是动态生成的,而不是预定义的并行流水线
- evaluator-optimizer: 如果存在一个清晰的验收标准,那么添加一个 feedback loop 可以显著提升输出质量
agents 的执行路径是动态生成的,无法预测准确执行步数和资源消耗。但是为了防止死循环等问题,应该对资源消耗、步数等预设停机条件。
👇 next
虽然人们喜欢说 agent 取代了 workflow,但是 agent 本身其实也是由一系列的 workflow 最小功能单元组成的。
区别在于,workflow 是由固定的逻辑和工具组成的。而 agent 则是由 LLM 动态选择工具和生成逻辑组成的。
本文介绍了用来构建 agent 的 workflow 功能单元:
- chain: 最常见的串行流水线
- routing: 动态判断任务类型,传递给不同的下游
- parallel: 并行处理多个任务
- orchestrating: 类似于 parallel,但是下游的任务是动态生成的,而不是预定义的并行流水线
- evaluator-optimizer: 如果存在一个清晰的验收标准,那么添加一个 feedback loop 可以显著提升输出质量
agents 的执行路径是动态生成的,无法预测准确执行步数和资源消耗。但是为了防止死循环等问题,应该对资源消耗、步数等预设停机条件。
👇 next
免费用户可以并行 2 个任务(声称是 3 个,实际上只能运行 2 个😓)。
选择好项目、branch 后,点击下面预设的 Performance、Design、Security 生成 prompt。然后建议把执行计划改为 Start(单次执行),而不是默认的 Scheduled,防止占用有限的任务配额。(如果你是尊贵的付费用户那请忽略)
免费用户只能选用 gemini-3-flash。我个人的使用体验是,它找 BUG 的能力非常强,但是修复的能力比较弱。我目前的使用方法是,把 BUG REPORT 粘贴给其他更强力的模型来修复,最近每天都能找出很多陈年老 BUG,每天都在打击我身为老程序员的自尊😭。
不过换个思路,这也是一个去刷开源项目 PR 的机会。
学习了一下 Anthropic 的 Agent Skills 设计。通过在文件系统中定义一套文件结构,让 Agent 可以按需加载(Progressive Disclosure)相关的技能描述和脚本。
Skills 通过 metadata + instructions + scripts 定义一个领域技能。Agent 在启动时全量加载 metadatas,然后按需加载 instructions,而 instructions 会指导 agent 调用 scripts。scripts 的内容不会被加载,只有 output 会被加载进入 context。
通过一个三层的 lazy-loading 设计,相当于 RAG + tools,既减少了对 context 的占用,也赋予了 agent 工具调用的能力。
但是我认为,Anthropic 没有选择优化 MCP,而是硬造了一个新轮子,给 Agent 世界带来更多的混乱,有些可惜。
Skills 的功能完全可以通过对 MCP 的些微优化来实现,只需要在 MCP 中增加两个 tools:
-
find_skills(query): 根据 query 查找相关的 skills metadata 列表-
describe_skill(skill_id): 根据 skill_id 获取对应的 instructions。instructions 内会指导 agent 如果通过调用其他 tools 完成任务。实际上,已经有很多人发布了相关的 skills-mcp 工具,只要搜索
github skills-mcp 就能找到很多。https://laisky.notion.site/msanft-CVE-2025-55182-Explanation-and-full-RCE-PoC-for-CVE-2025-55182-2c2ba4011a8681b89b60cf02827a6276?source=copy_link
之前提到的 next/react 严重服务端 RCE 漏洞 CVE-2025-55182
攻击者传递两个 chunk。chunk 0 作为攻击载体,chunk 1 作为正常 chunk,然后:
1. 利用自定义 then 将 chunk.prototype.then 挂载到 chunk 0,使得 chunk 0 变成 thenable,成为可被执行的 Promise
2. chunk 1 中,通过 $@0,将 chunk 0 作为 decodeReplyFromBusboy 的返回值,被 await 执行(thenable 对象都会被作为 Promise 而被 await 执行)
3. chunk0 中,通过自定义 react 状态机 status,触发 initializeModelChunk 中对 _response 的读取
4. 在 chunk 0 中,$B 会让 react 调用 response._formData.get()。但是 chunk 0 自定义了 _response 中的 _formData 和 _get,导致读取 _response body 的操作变成了一次代码执行
在我看来严重隐患似乎存在于两个地方:
1. 允许用户操作 prototype 的 function constructor,可以通过限制仅允许访问 ownProperty 来抑制
2. $@0 直接将 chunk 返回,而且 react 会将这个 chunk 视为一个可信的内部对象,这个对象通过 status 来控制状态,_response、_get 来控制数据。也就是说,外部的不可信输入直接控制了状态和数据。我觉得这个设计的问题可比 prototype 的访问越权严重多了。
之前提到的 next/react 严重服务端 RCE 漏洞 CVE-2025-55182
攻击者传递两个 chunk。chunk 0 作为攻击载体,chunk 1 作为正常 chunk,然后:
1. 利用自定义 then 将 chunk.prototype.then 挂载到 chunk 0,使得 chunk 0 变成 thenable,成为可被执行的 Promise
2. chunk 1 中,通过 $@0,将 chunk 0 作为 decodeReplyFromBusboy 的返回值,被 await 执行(thenable 对象都会被作为 Promise 而被 await 执行)
3. chunk0 中,通过自定义 react 状态机 status,触发 initializeModelChunk 中对 _response 的读取
4. 在 chunk 0 中,$B 会让 react 调用 response._formData.get()。但是 chunk 0 自定义了 _response 中的 _formData 和 _get,导致读取 _response body 的操作变成了一次代码执行
在我看来严重隐患似乎存在于两个地方:
1. 允许用户操作 prototype 的 function constructor,可以通过限制仅允许访问 ownProperty 来抑制
2. $@0 直接将 chunk 返回,而且 react 会将这个 chunk 视为一个可信的内部对象,这个对象通过 status 来控制状态,_response、_get 来控制数据。也就是说,外部的不可信输入直接控制了状态和数据。我觉得这个设计的问题可比 prototype 的访问越权严重多了。

https://www.notion.so/laisky/Cloudflare-outage-on-November-18-2025-2bcba4011a8681e79964ff8933d3c5b2
CloudFlare 对于 2025-11-18 的故障报告。边缘服务设定了严格的内存限制,其中bot modules 限制了能够处理的规则行数。当接收到超过限制的规则文件后导致 panic。而新的 FL2 系统在 bot modules panic 时,没能仅降级 bot 服务,而是全链路 panic,导致全站 5xx。旧版的 FL 系统就很好的仅降级了 bot score 服务,没有对用户业务造成中断。
我个人认为的经验教训就是:
1. bot modules panic 不是问题,有助于尽早暴露错误,但是必须被隔离。
2. FL2 在 bot modules panic 后,应该进行告警和服务降级,而不是整体 panic(Blast Radius)
3. chaos engineering 应该对各种交互都进行测试,比如文件过大、格式错误等等。任何关键服务都不应该信任外部输入,即使这个外部输入来自友方。
CloudFlare 对于 2025-11-18 的故障报告。边缘服务设定了严格的内存限制,其中bot modules 限制了能够处理的规则行数。当接收到超过限制的规则文件后导致 panic。而新的 FL2 系统在 bot modules panic 时,没能仅降级 bot 服务,而是全链路 panic,导致全站 5xx。旧版的 FL 系统就很好的仅降级了 bot score 服务,没有对用户业务造成中断。
我个人认为的经验教训就是:
1. bot modules panic 不是问题,有助于尽早暴露错误,但是必须被隔离。
2. FL2 在 bot modules panic 后,应该进行告警和服务降级,而不是整体 panic(Blast Radius)
3. chaos engineering 应该对各种交互都进行测试,比如文件过大、格式错误等等。任何关键服务都不应该信任外部输入,即使这个外部输入来自友方。
https://x.com/0xdizz/status/1996425682717720971?s=20 用 react 写服务端的赶紧自查一下。我这种坚持不碰前端佬写的服务端的后端仔有福了🐶
👉 next
👉 next
https://laisky.notion.site/Time-Zone-Handling-for-Software-Engineers-A-Comprehensive-Technical-Handbook-2b3ba4011a8680f2b895f51f19b62dad?source=copy_link
让 DeepResearch 帮忙总结了一篇关于时区的报告。最近都不怎么喜欢搜索文章了,想到什么问题就扔给 DeepResearch 让它给我写一篇报告。
因为中国只有一个时区,很多开发人员都会忽略时区问题,我加入很多团队都帮忙处理过时区相关的问题(另一个经常被忽略的是编码问题)。
首先,在用户看不见的后端使用 UTC 时间是一个很好的习惯,但是 UTC 并不是银弹,并不能取代时区。
时区并不仅仅只是相对于 UTC 的一个固定偏移量,而是代表某一地区时间变化的历史和规则。比如某地可能在某一个时刻,决定让时钟拨快或拨慢一小时,这些规则的处理都必须依赖准确的当地时区数据,而不是 UTC 能够解决的。同理,不同的时区也不能随意的互相替换,即使在当前时刻它们的 UTC 偏移量相同。
比如关于冬令时/夏令时的调整,就会导致当地的某一时刻在两个不同时区出现两次,而另一个时刻则根本不存在。
关于时间的存储,UTC 仅能满足对于时刻的存储需求。只要涉及到当地事件、时间的相对计算、日程安排(牵涉星期、月份日期、节假日)等,都必须结合使用当地时区信息进行计算。而且由于用户可能会进行跨时区迁移,最好能够让用户自行选择自己的时区信息(比如 Google Calendar 的做法)。
重点:
* 如果你只需要时刻信息(Instant),使用 UTC 存储和传输是一个好习惯。
* 但是如果你需要任何基于当地时间的计算,必须携带时区信息。
BTW,时区的英文缩写存在重名,在沟通中不要使用简写。比如 CST 既可以是 China Standard Time 也可以是 Central Standard Time。 我以前和美国的团队协作时就遇到过歧义。
让 DeepResearch 帮忙总结了一篇关于时区的报告。最近都不怎么喜欢搜索文章了,想到什么问题就扔给 DeepResearch 让它给我写一篇报告。
因为中国只有一个时区,很多开发人员都会忽略时区问题,我加入很多团队都帮忙处理过时区相关的问题(另一个经常被忽略的是编码问题)。
首先,在用户看不见的后端使用 UTC 时间是一个很好的习惯,但是 UTC 并不是银弹,并不能取代时区。
时区并不仅仅只是相对于 UTC 的一个固定偏移量,而是代表某一地区时间变化的历史和规则。比如某地可能在某一个时刻,决定让时钟拨快或拨慢一小时,这些规则的处理都必须依赖准确的当地时区数据,而不是 UTC 能够解决的。同理,不同的时区也不能随意的互相替换,即使在当前时刻它们的 UTC 偏移量相同。
比如关于冬令时/夏令时的调整,就会导致当地的某一时刻在两个不同时区出现两次,而另一个时刻则根本不存在。
关于时间的存储,UTC 仅能满足对于时刻的存储需求。只要涉及到当地事件、时间的相对计算、日程安排(牵涉星期、月份日期、节假日)等,都必须结合使用当地时区信息进行计算。而且由于用户可能会进行跨时区迁移,最好能够让用户自行选择自己的时区信息(比如 Google Calendar 的做法)。
重点:
* 如果你只需要时刻信息(Instant),使用 UTC 存储和传输是一个好习惯。
* 但是如果你需要任何基于当地时间的计算,必须携带时区信息。
BTW,时区的英文缩写存在重名,在沟通中不要使用简写。比如 CST 既可以是 China Standard Time 也可以是 Central Standard Time。 我以前和美国的团队协作时就遇到过歧义。

https://tee.fail/ wiretap 的团队继续发力,TEE 加密芯片对内存加密使用了确定性算法,同样的明文会生成同样的密文,导致可以通过内存分析破译私钥。继上次破解 SGX 老款芯片后,这次把最新款的 TDX 和 SEV-SNP 也攻破了,可以说 TEE 全军覆灭。
AMD 和 Intel 都表示不会修复,内存监听和改写不属于 TEE 的防御范畴。
看来,TEE 确实只能用来防内鬼,并不能构成一个可以放心地托管给别人的飞地。
* prev
AMD 和 Intel 都表示不会修复,内存监听和改写不属于 TEE 的防御范畴。
看来,TEE 确实只能用来防内鬼,并不能构成一个可以放心地托管给别人的飞地。
* prev
继续学习 Context Engineering 相关的文章,主要看了这两篇:
- 来自 Augment 的 《How we made code search 40% faster for 100M+ line codebases using quantized vector search》
- 来自 Anthropic 的 《Contextual Retrieval in AI Systems》
📒 关于 query 的性能:
1. 利用 ANN 大幅减少 embeddings vectors 数量,提高检索速度。
我理解类似于对向量进行聚类,然后只对聚类中心进行搜索,最后再在聚类内进行精确搜索。
但是不确定 Augment 是自己手写了一个 ANN 的聚合层,还是直接使用了类似 pg_vector 的 IVF 等功能。
2. 对 ANN 方案的优化,对 embeddings index 做 SNAPSHOT。只有搜索的 chunk 在 SNAPSHOT 中时才触发 ANN 加速,否则走传统的线性扫描。
这样就可以适应无时不刻都在动态更新的代码库。
📒 关于 query 的准确率和召回率:
1. embeddings vectors 擅长 semantic search,但对精确匹配不友好。结合 BM25 来提高精确匹配的能力。
2. 在 embeddings 以前,先为 chunk 添加上下文信息
有一个优化技巧是,先利用 prompt cache 缓存全文,然后再使用这个 cache 为每一个 chunk 生成上下文。
3. 玄学参数,每次 RAG 提供 20 个 context chunks 的效果最好。Anthropic 的做法是,用混合搜索检索出 400 个 chunks,然后使用 cohere rerank 选出 top20。
4. rerank 会带来额外的延迟,所以 chunks 数量和延迟是一个 trade-off。
👇 next
- 来自 Augment 的 《How we made code search 40% faster for 100M+ line codebases using quantized vector search》
- 来自 Anthropic 的 《Contextual Retrieval in AI Systems》
📒 关于 query 的性能:
1. 利用 ANN 大幅减少 embeddings vectors 数量,提高检索速度。
我理解类似于对向量进行聚类,然后只对聚类中心进行搜索,最后再在聚类内进行精确搜索。
但是不确定 Augment 是自己手写了一个 ANN 的聚合层,还是直接使用了类似 pg_vector 的 IVF 等功能。
2. 对 ANN 方案的优化,对 embeddings index 做 SNAPSHOT。只有搜索的 chunk 在 SNAPSHOT 中时才触发 ANN 加速,否则走传统的线性扫描。
这样就可以适应无时不刻都在动态更新的代码库。
📒 关于 query 的准确率和召回率:
1. embeddings vectors 擅长 semantic search,但对精确匹配不友好。结合 BM25 来提高精确匹配的能力。
2. 在 embeddings 以前,先为 chunk 添加上下文信息
有一个优化技巧是,先利用 prompt cache 缓存全文,然后再使用这个 cache 为每一个 chunk 生成上下文。
3. 玄学参数,每次 RAG 提供 20 个 context chunks 的效果最好。Anthropic 的做法是,用混合搜索检索出 400 个 chunks,然后使用 cohere rerank 选出 top20。
4. rerank 会带来额外的延迟,所以 chunks 数量和延迟是一个 trade-off。
👇 next
https://x.com/cr0ath/status/1978993127966019793?s=46
很有意思,安全相关的代码,要使用真随机,不要用伪随机,更不能手写随机。
眼见不为实,小心 unicode 特殊字符。
很有意思,安全相关的代码,要使用真随机,不要用伪随机,更不能手写随机。
眼见不为实,小心 unicode 特殊字符。
简单学习了一下 https://github.com/github/spec-kit,确实是一个很有趣的项目。
作为一个资深的开发者,在我看来,spec-kit 就是试图在扮演我每天都在做的事情,试图以标准化的方式完成从需求到产品的过程:
1. 模拟场景,撰写 user story。
2. 根据 user story,编写需求文档(相当于
3. 根据需求,撰写技术文档,进行可行性分析和系统设计(相当于
4. 根据技术文档,拆分开发任务。如果选择 TDD 的开发模式,则可以同步编写测试用例(相当于
5. 各个开发人员和测试人员,认领任务,进行开发和测试(相当于
在我的实际上和 AI 协作 coding 的经验看来,实际上还少了一个很关键的步骤,应该可以视为
我之前使用 Augment Code 时,发现它对每一个项目,都会维护一个全局的 memory,从而让 Agents 能够在一个统一的上下文中工作。这个 memory 里面,包含了项目的概要,需要关注的重要功能点,相关规范等等,类似于一个专注于当前项目的
我可以理解,对于那些对标准开发流程比较陌生的初级开发者而言,或者对于那些纯粹 vibe coding 的人而言,spec-kit 无疑是一个巨大的进步,显著提高了开发结果的确定性。不过,有一个地方让我觉得有点奇怪,spec-kit 居然需要开发者手动来逐步执行
从我个人来说,我不会考虑实际使用 spec-kit,有如下原因:
1. 作为一名资深开发者,我已经熟悉了标准的产品研发流程,不需要 spec-kit 用如此笨拙的方式来引导我,它的工作流在我看来过于粗糙。
2. 正如官方的视频介绍中所说,“spec-kit 让你只需要关心 What 和 Why,而不需要关心 How”。但是我认为,目前的模型能力还不足以让我完全不关心 How。
3. 为了降低成本,我倾向于尽可能减少和 AI 对话的次数,而 spec-kit 显然会大幅增加我和 AI 交互的频次。
综上,我认为 spec-kit 是一个很好的试图对 vibe coding 标准化的尝试。它就像一幅重型铠甲,如果你武艺平平,那么它会显著提高你的战斗力。但是对于那些武艺高强的武士而言,它反而会拖累你的身手,让你无法发挥出真正的实力。所以是否要采用它,取决于当前项目对于开发流程的 vibe 程度有多高。
我认为,spec-kit 的价值体现在:
1. 对于 vibe coder,作为一种提高标准化和确定性的工具,提高产品质量。
2. 对于和 AI 协作的开发者,提供了一个参考,可以用来优化开发流程和 prompt 设计。
3. 对于 agents 的设计者,提供了一个完整的和用户交互的流程,可以用来设计能够完成用户需求的 agents。
Ps. 我更倾向于认为,spec-kit 所提供的辅助,很快(或者已经)被强化学习或 fine-tuning 内化为模型本身的能力,而不需要外部的工具来辅助。
最后,我个人对开发模式的看法是,短期内 AI 编程 Agents 仍然和资深开发者存在一些本质上的差距,但是这并不影响它能够极大的提高开发效率,并且独立完成大量的产品。我认为,短期内两种不同类型的人类开发者角色将会并存:
1. 一种是白盒开发,人类开发者掌控核心的细节,AI 扮演辅助角色,帮助人类开发者提高效率。
2. 另一种是黑盒开发,也就是所谓的 vibe coding,AI 扮演主导角色,人类开发者主要负责提出需求和验收结果。
这两种模式都有其适合的场景和生存空间,具体选用什么工具和开发流程,还是要取决于具体的项目需求。
作为一个资深的开发者,在我看来,spec-kit 就是试图在扮演我每天都在做的事情,试图以标准化的方式完成从需求到产品的过程:
1. 模拟场景,撰写 user story。
2. 根据 user story,编写需求文档(相当于
/speckit.specify)。3. 根据需求,撰写技术文档,进行可行性分析和系统设计(相当于
/speckit.plan)。4. 根据技术文档,拆分开发任务。如果选择 TDD 的开发模式,则可以同步编写测试用例(相当于
/speckit.tasks 和 /speckit.checklist)。5. 各个开发人员和测试人员,认领任务,进行开发和测试(相当于
/speckit.implement)。在我的实际上和 AI 协作 coding 的经验看来,实际上还少了一个很关键的步骤,应该可以视为
/speckit.clarify 的补充,就是收集相关 工具、SDK、API 的详细使用文档,以便于 AI 能够理解和正确地使用这些工具。我之前使用 Augment Code 时,发现它对每一个项目,都会维护一个全局的 memory,从而让 Agents 能够在一个统一的上下文中工作。这个 memory 里面,包含了项目的概要,需要关注的重要功能点,相关规范等等,类似于一个专注于当前项目的
Agents.md 文件。这个文件,在 spec-kit 中被称为 constitution。我可以理解,对于那些对标准开发流程比较陌生的初级开发者而言,或者对于那些纯粹 vibe coding 的人而言,spec-kit 无疑是一个巨大的进步,显著提高了开发结果的确定性。不过,有一个地方让我觉得有点奇怪,spec-kit 居然需要开发者手动来逐步执行
specify、plan、tasks、checklist、implement 这些步骤,而不是直接让 AI 来直接完成这些步骤,对于 vibe coder 而言可能过于繁琐。从我个人来说,我不会考虑实际使用 spec-kit,有如下原因:
1. 作为一名资深开发者,我已经熟悉了标准的产品研发流程,不需要 spec-kit 用如此笨拙的方式来引导我,它的工作流在我看来过于粗糙。
2. 正如官方的视频介绍中所说,“spec-kit 让你只需要关心 What 和 Why,而不需要关心 How”。但是我认为,目前的模型能力还不足以让我完全不关心 How。
3. 为了降低成本,我倾向于尽可能减少和 AI 对话的次数,而 spec-kit 显然会大幅增加我和 AI 交互的频次。
综上,我认为 spec-kit 是一个很好的试图对 vibe coding 标准化的尝试。它就像一幅重型铠甲,如果你武艺平平,那么它会显著提高你的战斗力。但是对于那些武艺高强的武士而言,它反而会拖累你的身手,让你无法发挥出真正的实力。所以是否要采用它,取决于当前项目对于开发流程的 vibe 程度有多高。
我认为,spec-kit 的价值体现在:
1. 对于 vibe coder,作为一种提高标准化和确定性的工具,提高产品质量。
2. 对于和 AI 协作的开发者,提供了一个参考,可以用来优化开发流程和 prompt 设计。
3. 对于 agents 的设计者,提供了一个完整的和用户交互的流程,可以用来设计能够完成用户需求的 agents。
Ps. 我更倾向于认为,spec-kit 所提供的辅助,很快(或者已经)被强化学习或 fine-tuning 内化为模型本身的能力,而不需要外部的工具来辅助。
最后,我个人对开发模式的看法是,短期内 AI 编程 Agents 仍然和资深开发者存在一些本质上的差距,但是这并不影响它能够极大的提高开发效率,并且独立完成大量的产品。我认为,短期内两种不同类型的人类开发者角色将会并存:
1. 一种是白盒开发,人类开发者掌控核心的细节,AI 扮演辅助角色,帮助人类开发者提高效率。
2. 另一种是黑盒开发,也就是所谓的 vibe coding,AI 扮演主导角色,人类开发者主要负责提出需求和验收结果。
这两种模式都有其适合的场景和生存空间,具体选用什么工具和开发流程,还是要取决于具体的项目需求。