



很有趣的文章,介绍了常见的 LLM prompt injection 攻击案例。任何会接受外部信息的 LLM 都可以被外部攻击者操作。尤其当这个 LLM 具有 function calling/tools/agents 能力时,相当于也为外部攻击者赋予了这些强大的能力。首当其冲的就是各种基于 RAG 的应用,retriever 获取的内容都可以成为攻击者手中的利刃。
作者在此文以及他的其他文章中屡次表达出悲观的态度,认为 LLM 的 prompt injection 不可避免,我们只能接受这个前提,然后小心谨慎地设计我们的应用。
配图是一个经典的 indirect prompt injection 例子,在网页中插入肉眼不可见的内容,来误导 bing chat 的自动答复。
one-api 对 gemini-pro-vision 的支持有 bug,我提了 PR,或者考虑用我的 fork 版
ppcelery/one-api:latest。顺带分享个数据,上个月这站上去掉我以外的 12 个充值用户总共只花了 1 美元。gpt-plus 一个月的会员费足够我们用一年…
最近几天都在读这篇论文,关于 LLM RAG 方法的综述。总结了 RAG 技术的发展脉络和应用、评估方法。此文的优点在于非常全面,从预训练、fine-tuning 到 inference 的 RAG 流程都探讨到了。
附件的 pdf 里我对比较重要的信息做了标注和笔记,改天有空水篇博客整理一下🐦。
整理了一个 slide: https://s3.laisky.com/public/slides/LLM-RAG.slides.html#/
附件的 pdf 里我对比较重要的信息做了标注和笔记,改天有空水篇博客整理一下🐦。
整理了一个 slide: https://s3.laisky.com/public/slides/LLM-RAG.slides.html#/
https://laisky.notion.site/Metrics-for-Information-Retrieval-and-Question-Answering-Pipelines-d5d4e3beb820419ca494596e319befcf
一个笔记,用于度量 LLM RAG Retriever 性能的常用指标。包括 HR, Recall, Precision, MRR, mAP, NDCG, EM, F1 Score, SAS。
Ps. Retriever 也有寻回犬的意思,负责叼回猎物,在 RAG 里则是负责找回有用的附加信息。
一个笔记,用于度量 LLM RAG Retriever 性能的常用指标。包括 HR, Recall, Precision, MRR, mAP, NDCG, EM, F1 Score, SAS。
Ps. Retriever 也有寻回犬的意思,负责叼回猎物,在 RAG 里则是负责找回有用的附加信息。

https://youtu.be/V3BafEiqSFg?si=M0sZ9F4tLA5cSzad
最近看了部关于欧美核聚变研究的纪录片,其中一位科学家声称,预计 2035 年可以商业化,2040 年可以全球化。掐指一算,正好我小孩 20 岁步入社会的时候,世界上已经有无限的能源供给了,亦或说,无限的算力。
顺带一提核裂变,越来越多的人认为核裂变发电站是人类走的一条歧路,人总是会犯错的,而裂变站的每一次事故所造成的代价都是无法承受的,法国核能安全研究院估算每一次核事故会造成 3000~15000 亿欧元的损失。而且核裂变发电站的核废料处理也是一个难题。日本福岛核事故对欧美的冲击也是巨大的,毕竟日本人在欧美人心目中一直是“匠人精神”的代表,如果连日本人都搞不定核裂变,那么人们也就很难再相信它了。
但是在聚变等次世代技术真正成熟以前,核裂变是唯一清洁的稳定发电源(地热能、水能也是清洁的稳定能源,但是需要地理条件)。这可能就是人类能源史上的一次阵痛吧。
最近看了部关于欧美核聚变研究的纪录片,其中一位科学家声称,预计 2035 年可以商业化,2040 年可以全球化。掐指一算,正好我小孩 20 岁步入社会的时候,世界上已经有无限的能源供给了,亦或说,无限的算力。
顺带一提核裂变,越来越多的人认为核裂变发电站是人类走的一条歧路,人总是会犯错的,而裂变站的每一次事故所造成的代价都是无法承受的,法国核能安全研究院估算每一次核事故会造成 3000~15000 亿欧元的损失。而且核裂变发电站的核废料处理也是一个难题。日本福岛核事故对欧美的冲击也是巨大的,毕竟日本人在欧美人心目中一直是“匠人精神”的代表,如果连日本人都搞不定核裂变,那么人们也就很难再相信它了。
但是在聚变等次世代技术真正成熟以前,核裂变是唯一清洁的稳定发电源(地热能、水能也是清洁的稳定能源,但是需要地理条件)。这可能就是人类能源史上的一次阵痛吧。
https://x.com/qq3qiyu/status/1737728033384206710?s=20
看到有人讨论 python requests 的 timeout 问题,简而言之就是发现 requests 的总耗时会超过你设置的 timeout。
其实原理很简单,requests 支持两种 timeout:
* connect timeout: 建立连接的超时时间
* read timeout: 服务端每次响应的超时时间
默认情况下,timeout 设置的是 connect timeout + read timeout,你也可以通过 tuple 的形式分别设置。
需要注意的是,requests 并不支持 total timeout,就是实际上你没法控制这个 requests 请求总共会花多长时间。举一个极端的例子,如果这个服务端总能在每隔 read timeout 内回复点数据,那么这个请求实际上可以耗费无穷长的时间。
requests 官方的解释是,市面上已经有其他控制 total timeout 的包了,requests 没必要再做一个。这个第三方包就是 https://github.com/pnpnpn/timeout-decorator ,它通过设置
如果你使用 asyncio,那么
注意:
看到有人讨论 python requests 的 timeout 问题,简而言之就是发现 requests 的总耗时会超过你设置的 timeout。
其实原理很简单,requests 支持两种 timeout:
* connect timeout: 建立连接的超时时间
* read timeout: 服务端每次响应的超时时间
默认情况下,timeout 设置的是 connect timeout + read timeout,你也可以通过 tuple 的形式分别设置。
需要注意的是,requests 并不支持 total timeout,就是实际上你没法控制这个 requests 请求总共会花多长时间。举一个极端的例子,如果这个服务端总能在每隔 read timeout 内回复点数据,那么这个请求实际上可以耗费无穷长的时间。
requests 官方的解释是,市面上已经有其他控制 total timeout 的包了,requests 没必要再做一个。这个第三方包就是 https://github.com/pnpnpn/timeout-decorator ,它通过设置
ITIMER_REAL 信号来实现对函数总耗时的控制。但是这个包仅支持主线程。如果你使用 asyncio,那么
asyncio.wait_for 可以很轻松地为 coroutine 设置总耗时。aiohttp 的 timeout 看上去也是 total timeout。注意:
asyncio.wait_for 只是停止等待,杀 coroutine 需要另外手动处理(task.cancel())。被杀的 coroutine 也需要经常通过 await asyncio.sleep(0) 检查自己有没有被杀。https://laisky.notion.site/The-quantum-state-of-a-TCP-port-29b94af7bedf49beb958045c3c1dbc02
很有趣的关于 linux 上 TCP 本地端口自动分配的文章。
虽然理论上,TCP 连接只要求
这其中的逻辑错综复杂,以至于作者在文章标题中将其戏称为“量子态”。
结论:推荐使用
很有趣的关于 linux 上 TCP 本地端口自动分配的文章。
虽然理论上,TCP 连接只要求
(src_ip, src_port, dst_ip, dst_port) 的四元组不同,但实际情况复杂得多,即使使用了 SO_REUSEPORT 也不能保证本地端口一定能被复用,而且虽然 bind(2)/connect(2) 都支持自动分配本地端口,但对应的却是不同的处理逻辑。这其中的逻辑错综复杂,以至于作者在文章标题中将其戏称为“量子态”。
结论:推荐使用
IP_BIND_ADDRESS_NO_PORT & bind(2) 的方式绑定端口,可以最大化本地端口重用的概率。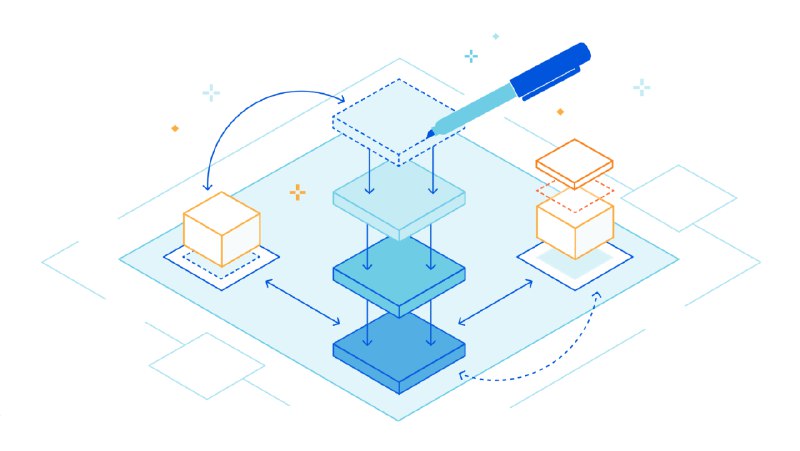
1. cost management 确实不准,在 billing period 结束后的 5 天内都可能大幅调整
2. invoice 页面可以下载详单,里面会记录所有的计费细节
我是不太理解啊,如果 budget 可能比账单晚 5 天,那这个 budget 的意义是什么?
最后是一个我忍不住一定要吐槽的,Azure 理解的 Model Version 跟我的直觉完全不一样。同一个 Model 的不同 Version 其实可能是完全不同的 Model,费用也完全不一样。
next: https://t.me/laiskynotes/121
CVE-2023-39325 利用 HTTP/2 单 tcp conn 上可以承载任意数量 stream 的特性,结合 stream rapid reset 的特性,实现超高强度的 DDoS 攻击。攻击者可以忽略 RTT,直接把己方的带宽跑满。
相当于在 HTTP/2 上打出了 UDP flood attack 的效果。前几个月各个被打趴的站盛传的“来自应用层”的攻击,基本都是这个。HTTP/3 也得考虑做相应的预防措施。
Go 的修复方式是将每个连接的 MaxConcurrentStreams 数设置为 250,起到一些缓解的作用。 https://github.com/golang/go/issues/63417